AI Credit Scoring in APAC: Why MAS and HKMA Are Scrutinizing Explainability Over Accuracy
AI is improving credit decisioning across Asia-Pacific. But regulators in Singapore and Hong Kong are increasingly focused on a different question: can the bank explain, in writing, why a specific customer was declined?
 For most of the past decade, credit scoring has been treated as a model performance problem - improve discrimination, reduce default rates, accelerate turnaround, and extend access to credit. As machine learning matured, alternative data, behavioral signals, device data, and transaction histories opened risk assessment capabilities that traditional scorecards couldn't match. The commercial case is well documented: McKinsey estimates generative AI alone could add $200 billion to $340 billion in annual value across global banking, with risk management and lending among the strongest use cases, and IDC's regional forecasts point to continued double-digit growth in AI spending across Asia-Pacific financial services as institutions scale automation and decision intelligence.
For most of the past decade, credit scoring has been treated as a model performance problem - improve discrimination, reduce default rates, accelerate turnaround, and extend access to credit. As machine learning matured, alternative data, behavioral signals, device data, and transaction histories opened risk assessment capabilities that traditional scorecards couldn't match. The commercial case is well documented: McKinsey estimates generative AI alone could add $200 billion to $340 billion in annual value across global banking, with risk management and lending among the strongest use cases, and IDC's regional forecasts point to continued double-digit growth in AI spending across Asia-Pacific financial services as institutions scale automation and decision intelligence.
None of that is in question anymore. What's in question is whether the decisions these models produce can be understood, justified, audited, and defended. And after a decade spent on both sides of model risk reviews for banks and digital lenders in this region, we can say with some confidence that this is where most AI credit scoring programmes actually stall. Not at the data science sign-off. At the governance review six months later, when someone asks the model to account for itself and it can't.
Why High-Performing Models Still Fail Governance Reviews
One of the most persistent misconceptions in AI lending is that model performance and model readiness are the same thing. They are not.
Data science teams optimize for predictive power: discrimination, calibration, false-positive rates, and by that measure, the model succeeds. Traditional credit scorecards offered something different: a level of transparency that risk teams and auditors found manageable, because decision factors traced directly to predefined variables and explicit business rules. When a customer was declined, the institution could generally say why, in a sentence, a non-technical reviewer could understand.
Machine learning breaks that simplicity. As models gain sophistication: gradient boosting, ensemble stacking, neural architectures, interpretability tends to decline. Variables interact non-linearly, in ways that resist intuitive explanation, and in some cases the team that built the model struggles to articulate precisely how a given decision was reached. This is what I'd call the explainability gap: the distance between what a model predicts and what the institution can confidently, faithfully explain.
In banking, a decision that can't be explained is usually a decision that can't be defended. That's not a technology problem the data science team can solve alone. It's a governance problem the architecture has to be designed for.
What MAS Actually Means by FEAT
Singapore's Fairness, Ethics, Accountability and Transparency (FEAT) principles get cited constantly in AI governance discussions and understood properly far less often. The common mistake is treating FEAT as a set of high-level values rather than an operational requirement.
Fairness isn't simply the absence of discrimination. Institutions need to demonstrate that AI outcomes don't systematically disadvantage groups in ways that can't be justified on legitimate risk grounds. Accountability isn't assigning ownership to a business unit on an org chart; it requires governance mechanisms that show, concretely, who is responsible for a decision an AI system influenced. Transparency doesn't mean exposing source code or model weights; it means outcomes can be explained to the people who need them explained: customers, auditors, regulators, internal review committees. Ethics sits above compliance; it asks whether the decision aligns with the customer's outcome the institution actually intends to produce.
MAS didn't leave FEAT as principle alone. Following the original 2018 FEAT release, MAS led an industry consortium Project “Veritas” to translate the principles into usable assessment methodologies and open-source tooling. The Veritas Toolkit's Transparency Assessment Methodology was developed jointly with Standard Chartered, HSBC, and TruEra, and applied specifically to credit risk scoring as a pilot use case, which tells you exactly where MAS expects this scrutiny to land hardest. The signal for banks operating in Singapore is clear: the regulatory conversation has already moved past whether AI should be used in credit decisioning, to how its governance gets operationalized and evidenced.
Why Feature Importance Is Not Explainability
A second, more technical misconception is just as common, and arguably more dangerous because it looks like compliance: the belief that explainability is solved once SHAP, LIME, or another feature-attribution method is bolted onto the model.
Feature attribution explains which variables influenced a prediction. It does not explain how the decision was reached, and on its own it does not create accountability. A regulator examining an adverse credit decision is rarely satisfied by a ranked list of contributing features in isolation. The actual questions look more like:
- Which data was used, and as of what point in time?
- Which model version generated this specific decision?
- What thresholds and policy rules were applied on top of the score?
- Was there a human override, and if so, on what basis?
- Can the decision be reproduced against the model state that existed at the time?

This is also where the distinction between a faithful explanation and a merely plausible one matters. A faithful explanation accurately reflects the computation that produced the decision. A plausible one, increasingly common where institutions retrofit a reason-code generator or an LLM-based summary on top of a black-box score, simply sounds reasonable after the fact, without describing the actual mechanism. Under audit, an unfaithful explanation is arguably worse than no explanation, because it manufactures a false paper trail.
Feature attribution contributes to explainability. It does not replace governance. Institutions that conflate the two tend to discover the gap only when a regulator or internal audit team asks for the full decision journey, not just the attribution chart.
Designing an Explainable Credit Decisioning Architecture
The institutions most likely to clear MAS and HKMA scrutiny aren't necessarily running the most sophisticated models. They're the ones that treated explainability as an architectural property from the start, not a reporting layer added before an audit.
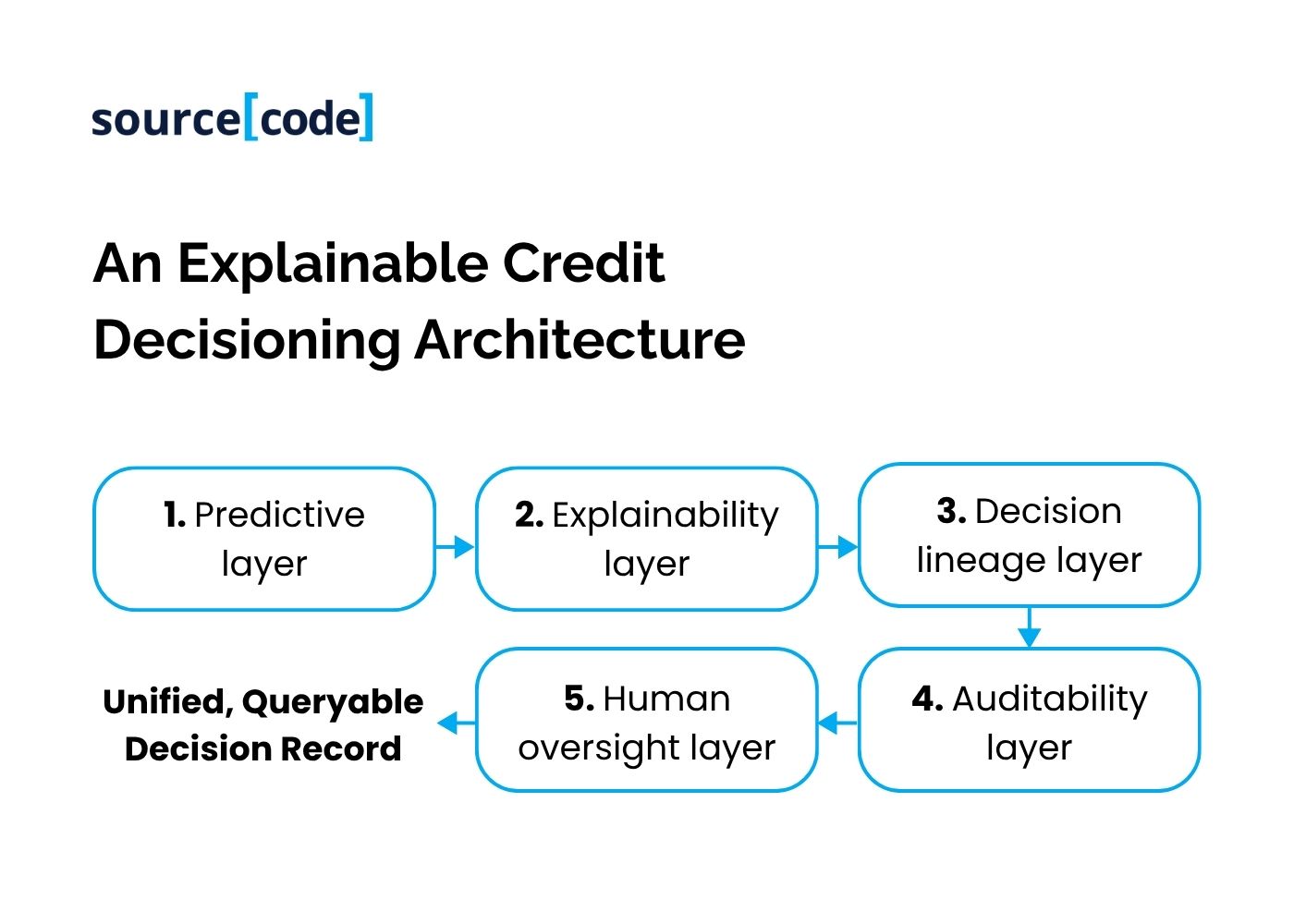 In practice, a defensible credit decisioning architecture separates into five layers. The predictive layer generates the risk score and lending recommendation. The explainability layer translates model output into decision factors a non-technical reviewer can understand, generated from the same computational path that produced the score, not reconstructed afterward by a separate process, which is the difference between a faithful and a plausible explanation. The decision lineage layer ties every recommendation back to its exact inputs, the specific model version that scored it, and the policy configuration in force at the time. The auditability layer preserves that record immutably, so a decision made fourteen months ago against a since-retired model remains explainable on demand. The human oversight layer captures escalations, overrides, and the rationale behind them as part of the same record, not a separate, looser process.
In practice, a defensible credit decisioning architecture separates into five layers. The predictive layer generates the risk score and lending recommendation. The explainability layer translates model output into decision factors a non-technical reviewer can understand, generated from the same computational path that produced the score, not reconstructed afterward by a separate process, which is the difference between a faithful and a plausible explanation. The decision lineage layer ties every recommendation back to its exact inputs, the specific model version that scored it, and the policy configuration in force at the time. The auditability layer preserves that record immutably, so a decision made fourteen months ago against a since-retired model remains explainable on demand. The human oversight layer captures escalations, overrides, and the rationale behind them as part of the same record, not a separate, looser process.
This is precisely the gap platforms like sBrain are built to close, generating decision-time, faithful explanations and the underlying audit record as a native part of the scoring pipeline, rather than a remediation project an institution has to build after its first regulatory inquiry.
The Missing Layer in Most Digital Banking Platforms
Digital banks have largely solved automated decision-making. Most have not solved automated accountability, and the gap between the two widens as lending volume grows.
The pressure to automate credit decisions often to a sub-five-minute turnaround - is commercially rational and well understood. But speed introduces a governance problem that doesn't show up until volume does: when a system makes thousands of decisions a day, manual explanation review becomes impossible, which means explainability has to operate at the same scale and the same latency as the decisioning itself, or it doesn't really exist in practice.
This is where many otherwise well-built platforms fall short. They automate scoring successfully, but the decision transparency that survives a regulator's sampling request, an internal audit, or a customer's adverse-action dispute was never built to operate at production scale, it exists as a manual process the data science team runs on request. That's workable for a handful of sampled cases during a model validation exercise. It's not workable for the explanation volume a live consumer lending book actually generates. The result is a highly efficient decisioning system that is, from a governance standpoint, quietly fragile.
HKMA Perspective on AI Lending
Hong Kong's framework runs on a related but distinct track. The HKMA's November 2019 high-level principles on AI in banking set out four pillars: governance and accountability, fairness, transparency and disclosure, data privacy and protection, and the authority has been explicit that these foundational principles remain highly relevant even as generative AI use cases expand across the industry.
What's particularly relevant for credit decisioning is the HKMA's consistent framing of human oversight as risk-calibrated rather than absolute. At the 2025 HKMA-AoF/HKIMR-CEPR conference on generative AI, Deputy Chief Executive Darryl Chan stated plainly that the "human-in-the-loop" element is a necessary safeguard depending on the risk associated with a given AI use case, under a supervisory approach he described as risk-based and technology-neutral. For a credit decisioning system, that's not a soft statement of intent, it's a concrete design requirement: a defensible human override path on every adverse decision, captured in the same audit record as the automated score, sized to the actual risk of the use case rather than applied uniformly or treated as a compliance afterthought.
Hong Kong's disclosure expectation also differs subtly from Singapore's emphasis on customer appeal and review rights: banks are expected to disclose to customers the purpose and limitations of AI used in the relevant decisioning process upfront. Institutions operating across both markets need an explanation layer that supports both regulatory postures, MAS's appeal-and-review framing and HKMA's upfront-disclosure framing, from a single underlying decision record, rather than maintaining two parallel compliance pipelines for what is functionally the same decision.
What HKMA and MAS Are Likely to Focus on Next
Several themes are converging across both regulators, and they point toward where scrutiny is heading rather than where it currently sits.
Model lineage - understanding not just the current model, but how it has evolved, and how each change affected decision outcomes over time. Decision traceability - the ability to reconstruct any historical decision and demonstrate how the outcome was actually generated, not just what the outcome was. Governance over human intervention - override and escalation mechanisms are drawing increasing supervisory interest as AI usage scales, particularly where overrides clusters in ways that could mask bias rather than correct for it. Ongoing monitoring - explainability is being treated less as a one-time deployment exercise and more as a continuous obligation across the model's operational life. And third-party model risk - as institutions increasingly license AI decisioning platforms rather than build entirely in-house, both MAS and HKMA have been consistent that accountability for the decision remains with the licensing institution, not the technology vendor. A vendor's explainability claims don't transfer governance responsibility; they just give the bank's risk team something specific to evidence.
Taken together, this is a shift in regulatory attention away from the algorithm itself and toward the operational system surrounding it, which is exactly where most institutions have under-invested relative to their model development spend.
Getting to Production-Ready
The honest diagnostic for a CTO isn't "do we have an explainability tool." It's a shorter, less comfortable set of questions:

- Can we produce a faithful, decision-time explanation for any adverse credit decision in the last 24 months, including ones scored by a model version we've since retired?
- Is that explanation generated from the same computational path that produced the score, or reconstructed afterward by a different process?
- Does our audit trail support an individual customer appeal or dispute without engineering involvement?
- Can our override process be evidenced as risk-calibrated and documented, rather than ad hoc?
- If our credit decisioning platform is licensed by a vendor, can we, not the vendor, produce the governance evidence a regulator asks for?
If the honest answer to more than one of these is "we'd have to build that," the institution has a model that works and a system that doesn't. Under MAS or HKMA scrutiny, it's the system that gets examined.
From Model Performance to Decision Defensibility
The AI-in-banking conversation spent years dominated by accuracy, for understandable reasons: the technology was new, and institutions needed proof it could outperform conventional approaches. That debate is largely settled. The next phase is governance, and the institutions that succeed in it won't necessarily be the ones with the best-performing models. They'll be the ones that can show, on demand, exactly how a decision was made, why it was made, and who remains accountable for it.
In Singapore and Hong Kong, explainability is moving from a technical feature to a strategic requirement. The question facing banks is no longer whether AI works. It's whether AI can be trusted under examination, and that, increasingly, is the competitive advantage that separates the next generation of digital lenders from the ones quietly remediating after their first model of risk review.
Key Takeaways for Banking Leaders
- High-performing AI models can still fail governance and regulatory review, model performance and model readiness are not the same thing.
- MAS FEAT and Project Veritas have shifted the conversation from AI adoption to AI accountability, with credit risk scoring already used as a pilot case for transparency assessment.
- Explainability requires more than feature attribution or SHAP values; regulators want the full decision journey: data, model version, thresholds, overrides, reproducibility.
- Decision lineage, auditability, and risk-calibrated human oversight are becoming architectural requirements, not optional add-ons.
- HKMA and MAS are converging on model lineage, traceability, override governance, ongoing monitoring, and third-party model risk as the next areas of focus.
- Licensing an AI decisioning platform does not transfer governance accountability, that responsibility stays with the institution.
- The next phase of AI lending will be defined less by predictive accuracy and more by decision defensibility.
Explore more: Learn how sBrain helps financial institutions build explainable AI credit decisioning systems with governance, auditability, and faithful decision-time explanations designed for regulated BFSI environments in Singapore and Hong Kong.
This article reflects practitioner experience advising banks and digital lenders on AI model risk and regulatory readiness across Singapore and Hong Kong. It is not legal advice; institutions should consult MAS and HKMA published guidance directly for compliance determinations specific to their use case.